矩阵分解
矩阵分解的概念
矩阵分解是指将一个矩阵分解成两个或者多个矩阵的乘积。譬如,一个N行M列的矩阵可以被分解为一个N行K列的矩阵和一个K行M列的矩阵的乘积(注意乘积顺序不能颠倒)。K可以理解为一个参数,这个参数会对这两个矩阵乘积产生的矩阵大小产生影响,但是不会影响乘积得到的矩阵的行数和列数。可以利用矩阵分解来解决很多实际生活中的问题。
例:
看图中的这个例子: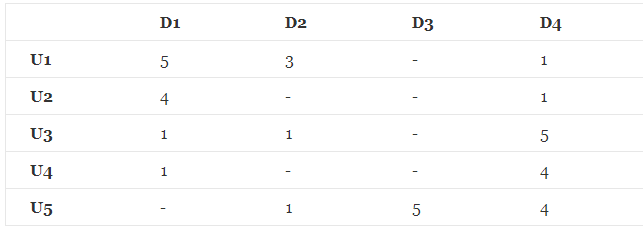 矩阵中,描述了5个用户(U1,U2,U3,U4 ,U5)对4个物品(D1,D2,D3,D4)的评分(1-5分),- 表示没有评分,我们的目的是把没有评分的给预测出来,然后按预测的分数高低,给用户进行物品推荐。
矩阵中,描述了5个用户(U1,U2,U3,U4 ,U5)对4个物品(D1,D2,D3,D4)的评分(1-5分),- 表示没有评分,我们的目的是把没有评分的给预测出来,然后按预测的分数高低,给用户进行物品推荐。
将图中的数据看作是一个维度为N×M的评分矩阵R,则R可以看做两个矩阵P(N×K)和Q(K×M)的乘积。对于P,Q矩阵的解释,直观上,P矩阵是N个用户对K个主题的关系,Q矩阵是K个主题跟M个物品的关系,或者说,N个用户通过K个主题对M个物品进行评分,那么我们在模拟时,也要通过这K个主题进行模拟。至于K个主题具体是什么,在算法里面K是一个参数,需要调节的,通常10~100之间。
具体步骤:
矩阵的分解(R是真实的评分矩阵,R^是我们预测得到的矩阵。R与R^越接近,就证明我们取得两个矩阵P和Q的预测模型越好。N和M是确定的参数值不会改变,因此K的取值对整个模型的预测结果起着至关重要的作用)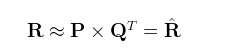
另外在这里补充说明一下矩阵相乘的规则:R^矩阵的第i行第j列的元素 = P 矩阵第i行的元素×Q矩阵第j列的元素。注意P和Q不能颠倒。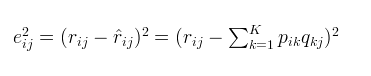
损失函数的平方等于真实值与预测值之间差值的平方,可以直接把预测值替换成P和Q的乘积。所以损失函数的值越小,真实值与预测值之间的差距越小,也就意味着我们拟合的结果越接近真实值,也就是我们对矩阵分解的结果越好。所以接下来就是解决问题的核心:基于梯度下降的优化算法。利用梯度下降的方法,一步步逼近损失函数的最小值
但是在机器学习中,我们通常在损失函数的后面加上一个正则项,公式如下: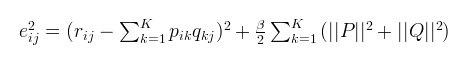
这样一来,我们也需要对算法做出一点改动
代码实现
import numpy as np
import matplotlib.pyplot as plt
def matrix(R, P, Q, K, alpha, beta):
result=[]
steps = 1
while 1 :
#使用梯度下降的一步步的更新P,Q矩阵直至得到最终收敛值
steps = steps + 1
eR = np.dot(P,Q)# dot(P,Q) 表示矩阵内积,即Pik和Qkj,
e=0
for i in range(len(R)):#len(R)代表的是R的行数
for j in range(len(R[i])):#这两行就是遍历R中的每一个元素
if R[i][j]>0:
#k由1到k的和,eij为真实值和预测值的之间的误差,
eij=R[i][j]-.dot(P[i,:],Q[:,j])
e=e+pow(R[i][j] - np.dot(P[i,:],Q[:,j]),2) #求误差函数值,我们在下面更新p和q矩阵的时候我们使用的是化简得到的最简式,较为简便,但下面我们仍久求误差函数值,这里e求的是每次迭代的误差函数值,用于绘制误差函数变化图
for k in range(K):#在上面的误差函数中加入正则化项防止过拟合
e=e+(beta/2)*(pow(P[i][k],2)+pow(Q[k][j],2))
for k in range(K):
#在更新p,q时我们使用化简得到了最简公式
P[i][k]=P[i][k]+alpha*(2*eij*Q[k][j]-beta*P[i][k])
Q[k][j]=Q[k][j]+alpha*(2*eij*P[i][k]-beta*Q[k][j])
#print('迭代轮次:', steps, ' e:', e)
result.append(e)#将每一轮更新的损失函数值添加到数组result末尾
#当损失函数小于一定值时,迭代结束
if eij<0.00001:
break
return P,Q,result
R=[
[5,3,0,1],
[4,0,0,1],
[1,1,0,5],
[1,0,0,4],
[0,1,5,4],
]
R=np.array(R)
alpha = 0.0001 #学习率
beta = 0.002
N = len(R) #表示行数
M = len(R[0]) #表示列数
K = 3 #3个因子
p = np.random.rand(N, K) #随机生成一个 N行 K列的矩阵
q = np.random.rand(K, M) #随机生成一个 M行 K列的矩阵
P, Q, result=matrix(R, p, q, K, alpha, beta)
print("矩阵R为:\n",R)
print("矩阵P为:\n",P)
print("矩阵Q为:\n",Q)
MF = np.dot(P,Q)
print("预测矩阵:\n",MF)
print()
#下面代码可以绘制损失函数的收敛曲线图
print("损失函数的收敛过程为:")
n=len(result)
x=range(n)
plt.plot(x, result,color='b',linewidth=3)
plt.xlabel("generation")
plt.ylabel("loss")
plt.show()
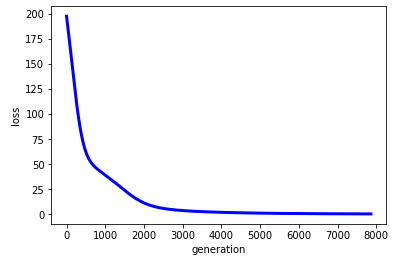
下面是运行的结果:
矩阵R为:
[[5 3 0 1]
[4 0 0 1]
[1 1 0 5]
[1 0 0 4]
[0 1 5 4]]
矩阵P为:
[[0.11646557 2.20824426 0.88565195]
[0.03596535 1.51168656 1.0372382 ]
[1.6897674 0.11533018 1.13699815]
[1.37709179 0.16820378 0.84690913]
[1.50038103 1.43928107 0.61271558]]
矩阵Q为:
[[-0.09628733 -0.1151309 1.07555694 2.32234973]
[ 1.97215153 0.90817549 1.96709116 -0.04825554]
[ 0.89544739 0.69563508 0.70044543 0.95484359]]
预测矩阵:
[[5.13683287 2.60815509 5.08943398 1.00957287]
[3.90660419 2.09027523 3.73883681 1.00097713]
[1.08286742 0.7011314 2.8407112 5.00432095]
[0.95748942 0.58335244 2.40522644 3.99863775]
[3.24266723 1.56060602 4.87411612 4.00000375]]
损失函数的收敛过程为: