推荐系统之协同过滤算法
推荐算法
1.什么是推荐算法
首先,在了解协同过滤算法之前,我们可以先了解一下推荐算法的概念。推荐算法是计算机专业中的一种算法,目前应用推荐算法比较好的地方主要是网络,其中淘宝做的比较好,但是作为一个老拼多多用户,我发现拼多多在这方面似乎比淘宝还要强一点。而推荐算法的原理就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西,推荐给客户。而近些年由于互联网的爆发,有了更大的数据量可以供我们使用,推荐算法才有了很大的用武之地。
2.推荐算法的条件
现在的各种各样的推荐算法,但是不管怎么样,都绕不开几个条件,这是推荐的基本条件
1.根据和你共同喜好的人来给你推荐 。
2.根据你喜欢的物品找出和它相似的来给你推荐 。
3.根据你给出的关键字来给你推荐,而这一部分实际上就是一个搜索算法。
4.根据上面的几种条件组合起来给你推荐。
3.推荐算法的分类
推荐算法实际上一共有三种分类:基于内容的推荐算法,协同过滤推荐算法,基于知识的推荐算法。
协同过滤算法
1.协同过滤算法理论基础
首先我们要明确一点,在协同过滤中有两种主流算法,一是基于用户的协同过滤,二是基于物品的协同过滤。他们之间的区别在于,基于用户的协同过滤就是将那些和你具有相同喜好的用户喜欢的东西推荐给你,而基于物品的协同过滤是将和你偏好的物品具有相似特征的物品推荐给你。但是实际上,这两者的原理是相同的,就是计算用户以及物品间的相似度,他们的核心部分都是解决相似度问题。所以在阐述这两种分类之前,我们先解决他们共同的核心问题:计算相似度。
(1)欧式距离的相似度测量
 又称欧几里得距离,用于计算两个样本数据之间的直线距离,这说明,欧式距离更加侧重于两个数据之间的绝对距离,而不太注重这两个数据在方向上的差异
又称欧几里得距离,用于计算两个样本数据之间的直线距离,这说明,欧式距离更加侧重于两个数据之间的绝对距离,而不太注重这两个数据在方向上的差异
(2)余弦距离衡量相似度
余弦相似度原理:用向量空间中的两个向量夹角的余弦值作为衡量两个个体间差异大小的度量,夹角角度越接近0°,余弦距离越接近1,也就是两个向量越相似,相似度越高;夹角角度越接近180°,余弦距离越接近0,也就是越不相似。这就叫做余弦相似。余弦相似度公式的推导比较麻烦,这里附上手写的一份。 以上我写的是用于计算两个样本数据之间的余弦值(相似度),相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
以上我写的是用于计算两个样本数据之间的余弦值(相似度),相比欧氏距离,余弦距离更加注重两个向量在方向上的差异。
借助三维坐标系来看下欧氏距离和余弦距离的区别: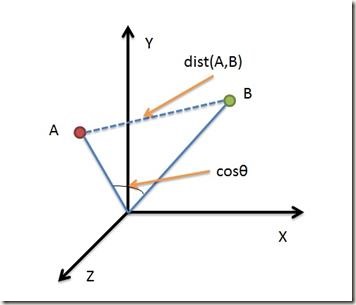 从上图可以看出,欧氏距离衡量的是空间各点的绝对距离,跟各个点所在的位置坐标直接相关;而余弦距离衡量的是两个空间向量的夹角,更加体现在方向上的差异。如果保持A点位置不变,B点朝原方向远离坐标轴原点,那么这个时候两点之间的余弦距离是保持不变的,但是欧式距离会发生改变;同样的,也会有欧式距离保持不变,余弦距离发生改变的情况。这就是欧氏距离和余弦距离之间的不同之处。
从上图可以看出,欧氏距离衡量的是空间各点的绝对距离,跟各个点所在的位置坐标直接相关;而余弦距离衡量的是两个空间向量的夹角,更加体现在方向上的差异。如果保持A点位置不变,B点朝原方向远离坐标轴原点,那么这个时候两点之间的余弦距离是保持不变的,但是欧式距离会发生改变;同样的,也会有欧式距离保持不变,余弦距离发生改变的情况。这就是欧氏距离和余弦距离之间的不同之处。
欧氏距离和余弦距离各自有不同的计算方式和衡量特征,因此它们适用于不同的数据分析模型
(3)杰卡德相似度
①杰卡德相似指数
简单来说就是计算两个集合的交集与并集的比值,这个比值结束杰卡德相似指数,用来表示两个集合之间的相似度。公式如下: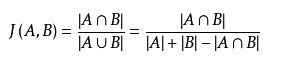 不难看出,这个比值介于0~1之间。杰卡德系数越接近1,说明两个集合之间的相似度越高;杰卡德系数越接近0,说明两个集合之间的相似度越低
不难看出,这个比值介于0~1之间。杰卡德系数越接近1,说明两个集合之间的相似度越高;杰卡德系数越接近0,说明两个集合之间的相似度越低
②杰卡德距离
杰卡德距离与杰卡德系数刚好相反。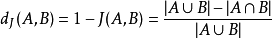 杰卡德距离的取值也是介于0~1之间,但是杰卡德距离用于描述两个集合的不相似度,杰卡德距离越接近1,两个集合越不相似;杰卡德距离越接近0,两个集合越相似。
杰卡德距离的取值也是介于0~1之间,但是杰卡德距离用于描述两个集合的不相似度,杰卡德距离越接近1,两个集合越不相似;杰卡德距离越接近0,两个集合越相似。
2.基于用户的协同过滤算法
(1)算法原理
它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,从而根据这一喜好程度来对目标用户进行推荐。通俗来讲,就是将和你喜好相似的用户偏爱的东西推荐给你。
(2)协同过滤的实现步骤
思路步骤:
1.计算其他用户和目标用户的相似度(使用欧氏距离算法);
2.根据相似度的高低找出K个目标用户最相似的邻居;
3.在这些邻居喜欢的物品中,根据邻居与你的远近程度算出每个物品的推荐度;
4.根据每一件物品的推荐度高低给你推荐物品。
(3)实例
来看一个例子。A,B,C,D四位用户购买a,b,c,d四种商品的情况如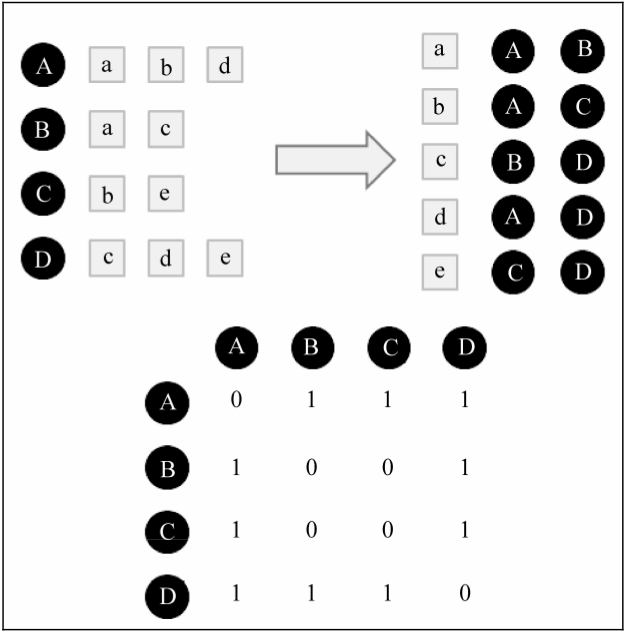 也就是先把每个用户购买商品的情况转换成每个商品的购买情况,然后利用这两份数据,得出一个矩阵,这个矩阵能够大致表明哪两个用户之间是会具有兴趣相似度的,然后计算用户之间的兴趣相似度,根据兴趣相似度较高的用户购买的产品来推荐。
也就是先把每个用户购买商品的情况转换成每个商品的购买情况,然后利用这两份数据,得出一个矩阵,这个矩阵能够大致表明哪两个用户之间是会具有兴趣相似度的,然后计算用户之间的兴趣相似度,根据兴趣相似度较高的用户购买的产品来推荐。
模块化实现
1.建立倒排矩阵
2.根据倒排矩阵计算每两个用户之间的兴趣相似度(这里采用余弦相似度)
3.排列出和推荐用户兴趣相似度前k个高的用户
4.根据兴趣相似度高的用户购买的产品来推荐并计算推荐度
1.定义
Python代码
import math
from operator import *
#例子中的数据相当于是一个用户字典{A:(a,b,d),B:(a,c),C:(b,e),D:(c,d,e)}
#我们这样存储原始输入数据
dic={'A':('a','b','d'),'B':('a','c'),'C':('b','e'),'D':('c','d','e')}#简单粗暴,记得加''
#定义一个函数来把用户的共同兴趣储存起来
def Usersim(dicc):#把用户-商品字典转成商品-用户字典(如图中箭头指示那样)
item_user=dict()#这里创建一个字典,用于存放转换后的数据
for u,items in dicc.items():#遍历我们输入的这个字典列表中的ABCD,u可以代指字典中的每个键(ABCD)或者说用户,item就是每个ABCD对应的元素
for i in items:#遍历每一个ABCD中的每个元素。文中的例子是不带评分的,所以用的是元组而不是嵌套字典。(元组类似于列表但是元组的元素不可修改)
if i not in item_user.keys():#如果这个元素不在新创建的这个字典的键里面(key()表示键)
item_user[i]=set()#每一个第一次被遍历到的元素(abcd)在此之前都不会存在于这个新的字典中,但是这一行之后就存在了,这样可以将每一个键都设置为set类类型方便操作。
item_user[i].add(u)#只要已经有了这个元素(abcd中的某一个),就向集合中添加这个元素所在的用户(ABCD)。
C=dict()#感觉用数组更好一些,真实数据集是数字编号,但这里是字符,这边还用字典。
N=dict()
for item,users in item_user.items():
for u in users:#遍历当前这个键中的每一个元素
if u not in N.keys():#u是元素,N.key是空的字典的键,所以u是肯定不在N.key里面的,所以这一行是为了初始化
N[u]=0 #因为这里的u遍历的是N,所以这里的作用还是初始化
N[u]+=1 #每个商品下用户出现一次就加一次,也就是说,N是用来储存每个用户一共购买的商品个数。
#但是这个值也可以从最开始的用户表中获得。
#比如: for u in dic.keys():
# N[u]=len(dic[u])
for v in users:
if u==v:#这个是用于判断,是否有两个用户购买了相同的产品,相等的话,就+1
continue
if (u,v) not in C.keys():#同上,没有初始值不能进行运算
C[u,v]=0
C[u,v]+=1 #这里还是一个字典,不过它的形状已经类似一个矩阵,它储存了所有购买重复的商品的用户的信息,以('A,B','1')的方式储存着。
#到这里倒排阵就建立好了,下面是计算相似度。这里我们采用的是余弦相似度的计算方式
W=dict()
for co_user,cuv in C.items():
W[co_user]=cuv / math.sqrt(N[co_user[0]]*N[co_user[1]])#因为我不是用的嵌套字典,所以这里有细微差别。
return W#这个W是每两个用户之间的相似度,它会把'A'和'B'之间的距离,'B'和'A'之间的距离都打印出来,尽管这两个距离相等
def Recommend(user,dicc,W2,K):
rvi=1 #这里都是1,实际中可能每个用户就不一样了。就像每个人都喜欢beautiful girl,但有的喜欢可爱的多一些,有的喜欢御姐多一些。
rank=dict()#定义一个字典用来储存推荐的商品和该商品的推荐度
related_user=[]#用于储存每个用户和待推荐用户的兴趣相似度
interacted_items=dicc[user]#储存待推荐用户已经过购买的商品
for co_user,item in W2.items():#遍历每一对用户相似度
if co_user[0]==user:#如果每一组用户相似度里的第一个用户等于我们所求的用户,也就是从所有数据里找出待推荐用户与每个人的兴趣相似度
related_user.append((co_user[1],item))#先建立一个和待推荐用户兴趣相关的所有的用户列表,也就是储存每个用户和待推荐用户的兴趣相似度
for v,wuv in sorted(related_user,key=itemgetter(1),reverse=True)[0:K]:#将每个用户和待推荐用户的兴趣相似度从大到小排列,取出前K个
#在这里,v是在这k个与待推荐用户兴趣相似度最大的人之中遍历,而wuv就是对应的兴趣相似度
for i in dicc[v]:#遍历"与待推荐用户兴趣相似度最大的用户"所购买的商品
if i in interacted_items:#这两行是排除待推荐用户和"与待推荐用户兴趣相似度最大的用户"所购买的重复的商品
continue #如果重复就跳过继续执行
if i not in rank.keys():#除去重复商品的剩下商品就是要推荐的,在这一行以及之前肯定是还没有储存近rank里,所以这一行的作用是先初始化为零,然后再加上兴趣相似度×具体的系数
rank[i]=0#先初始化
rank[i]+=wuv*rvi#然后存入推荐度,也就是兴趣相似度×具体的系数
return rank
if __name__=='__main__':
W3=Usersim(dic)
Last_Rank=Recommend('B',dic,W3,2)
print(W3)
print (Last_Rank)
首先是输出每两个用户之间的兴趣相似度:
{('A', 'B'): 0.4082482904638631, ('B', 'A'): 0.4082482904638631, ('A', 'C'): 0.4082482904638631, ('C', 'A'): 0.4082482904638631, ('A', 'D'): 0.3333333333333333, ('D', 'A'): 0.3333333333333333, ('B', 'D'): 0.4082482904638631, ('D', 'B'): 0.4082482904638631, ('C', 'D'): 0.4082482904638631, ('D', 'C'): 0.4082482904638631}
然后,输入不同的用户,会给出不同的商品和商品推荐度比如输入'A':
{'c': 0.4082482904638631, 'e': 0.4082482904638631}
再比如输入b:
{'b': 0.4082482904638631, 'd': 0.8164965809277261, 'e': 0.4082482904638631}