线性回归
2020-07-11
4 min read
1.该样本回归方程就是我我们需要拟合的曲线:
h(x) = θ0 + θ1x;
2.得出关于该回归方程的误差函数: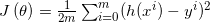
3.对误差函数求导:
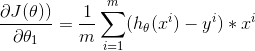
4.之后更新的到的θ0 和 θ1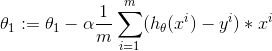 (公式里的α是学习率,我们可以象征性地理解为步长)
(公式里的α是学习率,我们可以象征性地理解为步长)
5.接下来,利用梯度下降的方法。这里我们可以分别使用批量梯度下降和随机梯度下降的方法来实现**(有助于更加具体地理解这两种梯度下降的算法)**
(1)批量梯度下降算法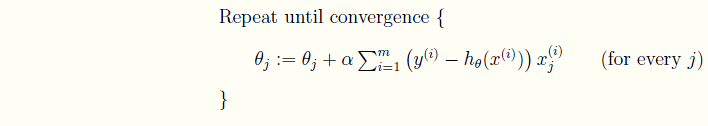 (上标i代表具体的某一个数据;xj代表系数θj对应的因变量)
(上标i代表具体的某一个数据;xj代表系数θj对应的因变量)
每一次的迭代,都把从θ0 到 θj的每一个参数进行迭代;而每一次对每一个参数进行迭代时,都需要把全部的样本都使用一遍,这样重复迭代直到θj收敛为止。所以说该算法的复杂度是O(i(j+1))
(为了防止我忘了,我写了一个一看就懂的版本)

(2)随机梯度下降法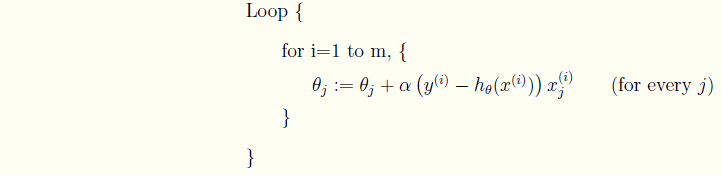
每一次的迭代,都把从θ0 到 θj的每一个参数进行迭代;而每一次对每一个参数进行迭代时,只使用所有样本中的一个数据,一旦到达最大的迭代次数或是满足预期的精度,就停止。这样算法的复杂度为O(j+1),就下降了很多。
(还是一个一看就会的版本)
批量梯度下降算法
@author:
"""
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
#数据
a = np.random.standard_normal((1, 500))
x = [150,200,250,300,350,400,600]#自变量x
y = [6450,7450,8450,9450,11450,15450,18450]#因变量y
y = y - a*10
y = y[0]
def Optimization(x,y,theta,learning_rate):
for i in range(iter):#批量梯度下降算法的核心,iter是最大迭代的次数。
theta = Updata(x,y,theta,learning_rate)更新参数用的函数
return theta#这是全部迭代之后的最后一组参数值
def Updata(x,y,theta,learning_rate):
m = len(x)#因变量的长度,即每次迭代的次数
sum = 0.0
sum1 = 0.0
alpha = learning_rate
h = 0
for i in range(m):#每一次迭代,都用到全部的样本数据
h = theta[0] + theta[1] * x[i]#一元线性回归方程,即我们需要拟合的曲线。
sum += (h - y[i])
sum1 += (h - y[i]) * x[i]
theta[0] -= alpha * sum / m #更新theta[0]
theta[1] -= alpha * sum1 / m #更新theta[1]
return theta#每一次迭代都输出更新后的参数
#数据初始化
learning_rate = 0.001#学习率
theta = [0,0]#最开始的参数值
iter = 1000#循环的次数
theta = Optimization(x,y,theta,learning_rate)
plt.rcParams['font.sans-serif']=['SimHei']#该函数用来定义图形的各种默认属性,比如字符显示,线条样式,窗口大小,坐标轴宽度等等属性
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(35,35))
plt.scatter(x,y,marker='o')
plt.xticks(fontsize=40)
plt.yticks(fontsize=40)
plt.xlabel('特征X',fontsize=40)
plt.ylabel('Y',fontsize=40)
plt.title('样本',fontsize=40)
plt.savefig("样本.jpg")
'''
#可视化
b = np.arange(0,50)
c = theta[0] + b * theta[1]
plt.figure(figsize=(35,35))
plt.scatter(x,y,marker='o')
plt.plot(b,c)
plt.xticks(fontsize=40)
plt.yticks(fontsize=40)
plt.xlabel('特征X',fontsize=40)
plt.ylabel('Y',fontsize=40)
plt.title('结果',fontsize=40)
plt.savefig("结果.jpg")