梯度下降法
#基本思想
假设我们爬山,如果想最快的上到山顶,那么我们应该从山势最陡的地方上山。也就是山势变化最快的地方上山
同样,如果从任意一点出发,需要最快搜索到函数最大值,那么我们也应该从函数变化最快的方向搜索。
函数变化最快的方向是什么呢?函数的梯度。
假如函数为一元函数,梯度就是该函数的倒数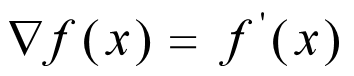
如果为二元函数,梯度定义为: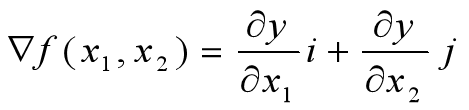 (此处用到高数偏导数的知识来求二元函数的倒数)
(此处用到高数偏导数的知识来求二元函数的倒数)
如果需要找的是函数极小点,那么应该从负梯度的方向寻找,该方法称之为梯度下降法。
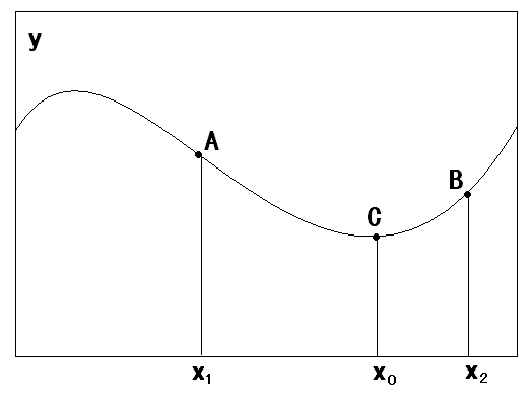 要搜索极小值C点,在A点必须向x增加方向搜索,此时与A点梯度方向相反;在B点必须向x减小方向搜索,此时与B点梯度方向相反。总之,搜索极小值,必须向负梯度方向搜索。
要搜索极小值C点,在A点必须向x增加方向搜索,此时与A点梯度方向相反;在B点必须向x减小方向搜索,此时与B点梯度方向相反。总之,搜索极小值,必须向负梯度方向搜索。
假设函数 y = f(x1,x2,......,xn) 只有一个极小点。初始给定参数为 X0 = (x10,x20,......xn0) 从这个点如何搜索才能找到原函数的极小值点?
方法:
- 首先设定一个较小的正数η,ε;
- 求当前位置处的各个偏导数:
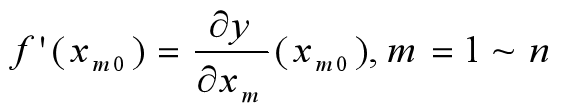
- 修改当前函数的参数值,公式如下:
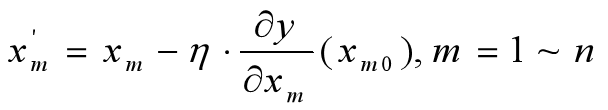
- 如果参数变化量小于,退出;否则返回2。
例:任给一个初始出发点,设为x0=-4,利用梯度下降法求函数y=x²/2-2x的极小值。
准备工作:
(1)给定两个参数值η = 0.9,ε = 0.01(η即为学习效率,或者步长)
(2)计算导数:dy/dx = x - 2;
一.(1)计算当前导数值:y' = -4 - 2 = -6;
(2)修改当前的参数值:x = x-ηy' = -4 - 0.9*(-6) = 1.4;
(3)计算△x = -0.9 * (-6)= 5.4。
(4)将△x与ε进行比较,如果△x<=ε ,则变化量满足终止条件,终止循环,输出参数x;
如果△x>ε,则继续进行循环
通过比较,可知△x>ε,继续进行循环
二.(1)计算当前导数值:y' = 1.4 - 2 = -0.6;
(2)修改当前的参数值:x = x-ηy' = 1.4 - 0.9*(-0.6)= 1.94;
(3)计算△x = -0.9 * (-0.6)= 0.54。
(4)将△x与ε进行比较,如果△x<=ε ,则变化量满足终止条件,终止循环,输出参数x;
如果△x>ε,则继续进行循环
通过比较,可知△x>ε,继续进行循环。
三.(1)计算当前导数值:y' = 1.94 - 2 = -0.06;
(2)修改当前的参数值:x = x-ηy' = 1.94 - 0.9*(-0.06)= 1.994;
(3)计算△x = -0.9 * (-0.06)= 0.054。
(4)将△x与ε进行比较,如果△x<=ε ,则变化量满足终止条件,终止循环,输出参数x;
如果△x>ε,则继续进行循环
通过比较,可知△x>ε,继续进行循环。
四.(1)计算当前导数值:y' = 1.994 - 2 = -0.006;
(2)修改当前的参数值:x = x-ηy' = 1.994 - 0.9*(-0.006)= 1.9994;
(3)计算△x = -0.9 * (-0.006)= 0.0054。
(4)将△x与ε进行比较,如果△x<=ε ,则变化量满足终止条件,终止循环,输出参数x;
如果△x>ε,则继续进行循环
通过比较,可知△x<=ε,则终止循环,输出此时的x即为函数的极小点。
python代码实现
#解决实例的Python代码
import numpy as np
inport matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.family'] = 'sans-serif'
mpl.rcParams['font.sans-serif'] = 'SimHei'
mpl.rcParams['axes.unicode_minus'] = false
#构建一维元素图形
def f1(x):
return 0.5 * (x ** 2) - 2x
def h1(x):
return x-2
#使用梯度下降法
GD_X = []
GD_Y = []
x = -4
alpha = 0.9
f_change = np.abs(alpha * hl(x))
f_current = f_change
GD_X.append(x)
GD_Y.append(f_current)
#迭代次数
iter_num = 0
while f_change >0.01 and iter_num<10:
iter_num+=1
x = x - x - alpha * h1(x)
tem = f1(x)
f_change = np.abs(alpha * hl(x))
f_current = tmp
GD_X.append(f_current)
print(u'最终的结果:(%.5f,%.5f)'%(x,f_current))
pirnt(u'迭代次数:%d'%iter_num)
printf(GD_X)
#损失函数
学习了梯度下降之后,我们引入新的概念:损失函数。便于我们直接利用梯度下降法计算损失函数的最小值。
我们可以近似地将损失函数理解为方差或者平方差。根据给出的一系类数据我们可以得出相关的函数,再根据该函数和不同变量,我们可以得出不同变量对应的不同的函数值。而每个函数值和每个真实的数值之间有一定的误差,根据这些误差我们可以得到相关的函数,即损失函数。损失函数的值越小,我们之前得到的函数就越精确。
例:根据某组数据得到预测的函数:h(x) = θ₁ + θ₂x。只含有一个特征/输入变量。在这个式子中θ₁,θ₂都是未知参数,x是已知数据。我们的目的是得到合适的参数使得我们的预测尽可能准确。这时就需要引入损失函数的概念。
 (暂时不用管1/2)
(暂时不用管1/2)
上图中的J(θ₁,θ₂)是一个关于θ₁和θ₂的二元函数,也就是损失函数。在三维空间坐标系内,存在一对点(θ₁,θ₂)使得J(θ₁,θ₂)有最小值
然后对损失函数进行一个简单的推导(利用梯度下降的算法)
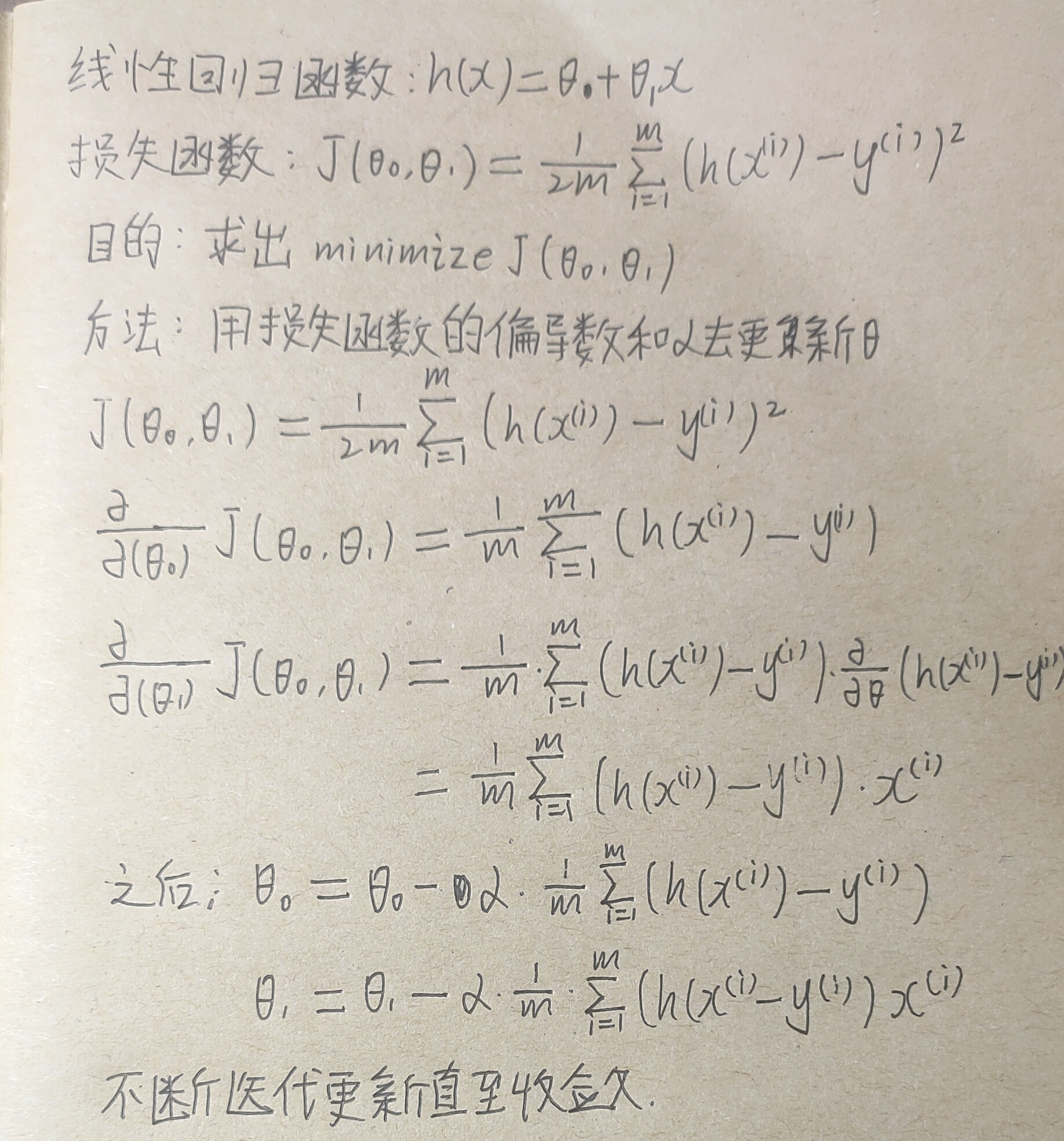 (在这个公式里突然多了一个α,它表示的是学习率,用来限定步长的大小,也很容易理解,毕竟得到的偏导是类似斜率的东西,只是一个方向,总得加个数值,才能表示向这个方向移动的距离。
(在这个公式里突然多了一个α,它表示的是学习率,用来限定步长的大小,也很容易理解,毕竟得到的偏导是类似斜率的东西,只是一个方向,总得加个数值,才能表示向这个方向移动的距离。
对于的取值,一般都取的比较小,但也不要太小,太小就意味着迭代步数要增加,运算时间边长。另外,迭代的步数要自己设置。
原文链接:https://blog.csdn.net/i96jie/java/article/details/81206473)
#梯度下降法的三个变种
了解了梯度下降法的核心思想以及损失函数后,我们接着了解梯度下降法的三个变种
1.批量梯度下降法(BGD)
其需要计算整个训练集的梯度,即: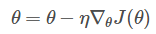 其中η为学习率,用来控制更新的“力度”/"步长"。
其中η为学习率,用来控制更新的“力度”/"步长"。
优点:
对于凸目标函数,可以保证全局最优; 对于非凸目标函数,可以保证一个局部最优。
2.随机梯度下降算法(SGD)
仅计算某个样本的梯度,即针对某一个训练样本 xi及其label yi更新参数: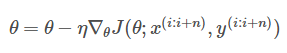 逐步减小学习率,SGD表现得同BGD很相似,最后都可以有不错的收敛。
逐步减小学习率,SGD表现得同BGD很相似,最后都可以有不错的收敛。
优点:
更新频次快,优化速度更快; 可以在线优化(可以无法处理动态产生的新样本);一定的随机性导致有几率跳出局部最优(随机性来自于用一个样本的梯度去代替整体样本的梯度)。
3.小批量梯度下降算法(MBGD),计算包含n个样本的mini-batch的梯度:MBGD是训练神经网络最常用的优化方法。
优点:
参数更新时的动荡变小,收敛过程更稳定,降低收敛难度;可以利用现有的线性代数库高效的计算多个样本的梯度。