KNN算法
1.算法简述
邻近算法,或者说K最近邻(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法。
2.算法详述
我们可以通过几幅图来形象地了解KNN算法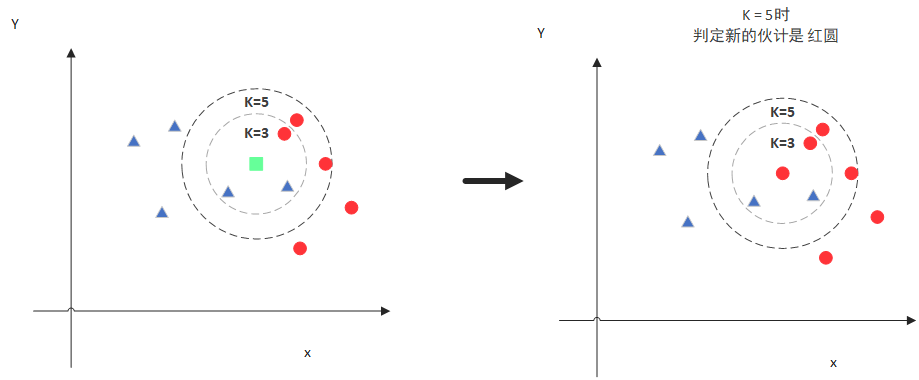 毫无疑问,k值的选定对于分类的效果至关重要。如果K值过小,拟合的效果不好;如果K值过大,就会覆盖过多的样本数据,失去拟合的意义。
毫无疑问,k值的选定对于分类的效果至关重要。如果K值过小,拟合的效果不好;如果K值过大,就会覆盖过多的样本数据,失去拟合的意义。
要度量空间中点距离的话,有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离(或欧几里得距离)等等。不过通常KNN算法中使用的是欧式距离,这里只是简单说一下,拿二维平面为例,,二维空间两个点的欧式距离计算公式如下: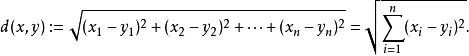 这样一来,不难得出,KNN算法最简单粗暴的方式就是计算预测点和所有样本点之间的距离,选出前K个距离最小的点看看哪个种类的点的数量最多。
这样一来,不难得出,KNN算法最简单粗暴的方式就是计算预测点和所有样本点之间的距离,选出前K个距离最小的点看看哪个种类的点的数量最多。
3.具体步骤
1.计算所有测试数据到一个训练数据之间的距离
2.将这些距离按照从小到大的顺序储存起来
3.取出最小的前k个点,
4.确定这k个点出现的类别的频率
5.返回前K个点中出现频率最高的类别作为测试数据的预测分类。
6.重复步骤1-5
4.KNN特点
KNN是一种非参的,惰性的算法模型。什么是非参,什么是惰性呢?
非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训练(tranning),最后才会得到一个算法模型。而KNN算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。
KNN算法的优势和劣势
了解KNN算法的优势和劣势,可以帮助我们在选择学习算法的时候做出更加明智的决定。那我们就来看看KNN算法都有哪些优势以及其缺陷所在!
KNN算法优点
简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
预测效果好。
对异常值不敏感
KNN算法缺点
对内存要求较高,因为该算法存储了所有训练数据
预测阶段可能很慢
对不相关的功能和数据规模敏感
KNN 算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。因此,基于python已经有很多成熟的可以直接使用的库来进行算法的实现
KNN算法的简单实现:(调用sklearn自带的库)
from sklearn import neighbors #sklearn中的函数集
from sklearn import datasets #sklearn中的数据集
knn = neighbors.KNeighborsClassifier() # 申明对象
iris = datasets.load_iris() # 导入数据(一个数据集,很大的数据集)
print(iris)
knn.fit(iris.data,iris.target) # 生成KNN模型,fit()函数可以理解为一个训练的过程
predicit_label = knn.predict([[0.2,0.3,0.3,0.2]]) # 预测这个数组的概率
print(predicit_label)
KNN算法的具体实现:
(也是copy别人的代码,自己加的注释)
'''
导入数据
filename数据存储路径
radio,按指定比例将数据划分为训练集和测试集
trainSet:训练数据
testSet:测试数据
'''
def loadDateset(filename,radio,trainSet=[],testSet=[]):
with open(filename,'rt') as csvfile: #打开filename;csvfile是一种文件格式
lines = csv.reader(csvfile) # 逐行读取数据
dataset = list(lines) # 将文件中的样本数据转换为列表类型存储
for x in range(len(dataset)-1): # 循环每行数据,将前4个特征值存入数组
for y in range(4):
dataset[x][y] = float(dataset[x][y])#也就是将前四列更新成浮点数
if random.random()<radio: # 根据radio的大小将样本数据集划分为训练数据和测试数据
trainSet.append(dataset[x])
else:
testSet.append(dataset[x])
'''
计算2个样例之间的距离(欧氏距离),length表示数据的维度
'''
def evaluateDistance(instance1,instance2,length):#变量为两个样例,还有维度
distance = 0#初始化距离
for x in range(length): # 循环每一维度,数值相减并对其平方,然后进行累加
distance += pow((instance1[x]-instance2[x]),2)
return math.sqrt(distance) # 开方求距离
'''
对于一个实例,找到离他最近的k个实例
'''
def getNeighbors(trainSet,testInstance,k):
distance = []
length = len(testInstance)-1 # 每个测试实例的维度(比如(2,3,4)就是三个维度)
for x in range(len(trainSet)-1):
dist = evaluateDistance(testInstance,trainSet[x],length)# 分别计算一个测试实例到每一个训练数据的距离
distance.append((trainSet[x],dist)) # 将每一个训练实例和其对应到测试实例的距离存储到列表(append()函数用于在列表末尾增添新的对象)
distance.sort(key=operator.itemgetter(1)) #进行排序,而排序的关键是元素第二维数据的大小,也就是dist
neighbors = [] # 用来存储离一个实例最近的几个测试数据
for x in range(k): # 取distance中前k个实例存储到neighbors
neighbors.append(distance[x][0])#已经经过排序的distance列表,取出前k个元素,就是一个测试实例的k个近邻
return neighbors
'''
在最近的K个实例中投票,少数服从多数,把要预测的实例归到多数那一类
'''
def getResponse(neighbors):#neighbors作为变量
classvotes = {} # 定义一个字典,存储每一类别的数目
for x in range(len(neighbors)):#遍历每一个k近邻的距离值大小
response = neighbors[x][-1]#表示第x行最后一列的元素
if response in classvotes:
classvotes[response] += 1
else:
classvotes[response] = 1
sortedVotes = sorted(classvotes.items(),key=operator.itemgetter(1),reverse=True) # 排序,输出数目最大的类别
return sortedVotes[0][0]
'''
计算测试集的准确率
'''
def getAccuracy(testSet,predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]: # 每行测试用例最后一列的标签与预测标签是否相等
correct += 1
return (correct/float(len(testSet)))*100.0
def main():
trainSet = [] # 存储训练集
testSet = [] # 存储测试集
radio = 0.80 # 按4:1划分
loadDateset('G:/PycharmProjects/Machine_Learning/KNN/irisdata.txt',radio,trainSet,testSet) #导入数据并划分
print("trainSetNum: "+ str(len(trainSet)))
print("testSetNum: "+ str(len(testSet)))
predictions = []
k = 3 # 选取前k个最近的实例
for x in range(len(testSet)): # 循环预测测试集合的每个实例
neighbors = getNeighbors(trainSet,testSet[x],k)
result = getResponse(neighbors)
predictions.append(result)
print('>predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet,predictions)
print('Accuracy: ' + repr(accuracy) + '%')
if __name__ == '__main__':
main()