K-means算法
1.算法概述
K-means,算法,简称聚类算法,通俗来讲,就是把一个区域中的所有点按照距离的远近,划分为若干个类别的算法,直观上表现为聚在一起的点分为一类。
我们可以通过以下几张图片来直观感受一下:
对于同样的一组样本数据,如果我们需要将数据分为两类,如下图:
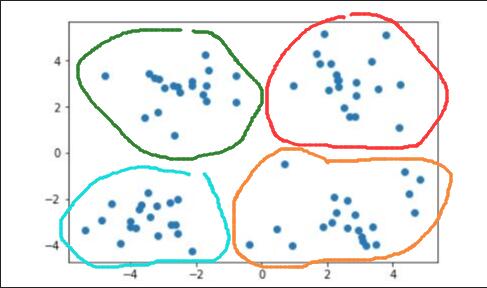
2.算法核心思想
K-means聚类算法是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心(就是要把所有的数据分为k个聚类),然后计算每个样本数据与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心,成为这一聚类。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
3. 算法实现步骤
1、首先确定一个k值,即我们希望将数据集经过聚类得到k个集合。
2、从数据集中随机选择k个数据点作为质心。
3、对数据集中每一个点,计算其与每一个质心的距离(如欧式距离),离哪个质心近,就划分到那个质心所属的集合。
4、把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。
5、如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终止。(在这里我们规定终止条件为聚类中心不再发生变化。在不同的实验中我们可以规定不同的终止条件)
6、如果新质心和原质心距离变化很大,需要迭代3~5步骤。
4. K-means算法优缺点
优点:
1、原理比较简单,实现也是很容易,收敛速度快。
2、当结果簇是密集的,而簇与簇之间区别明显时, 它的效果较好。
3、主要需要调参的参数仅仅是簇数k。
缺点:
1、K值需要预先给定,很多情况下K值的估计是非常困难的。
2、K-Means算法对初始选取的质心点是敏感的,不同的随机种子点得到的聚类结果完全不同 ,对结果 影响很大。
3、对噪音和异常点比较的敏感。用来检测异常值。
4、采用迭代方法,可能只能得到局部的最优解,而无法得到全局的最优解。
5.代码实现(自己的注释和理解)
#导入numpy库
from numpy import *
#K-均值聚类辅助函数
def numpy import *#文本数据解析函数
dataMat=[]
fr=open(fileName)
for line in fr.readlines():#读取文件的每一行直到结束,然后返回一个列表
curLine=line.strip().split('\t')#以制表的分隔符为界限分开,去掉前后的空格或者换行符,制表符
fltLine=map(float,curLine)#将每一行的数据映射成float型
dataMat.append(fltLine)#将数据添加至
return dataMat
def distEclud(vecA,vecB):
return sqrt(sum(power(vecA-vecB,2)))#数据向量计算欧式距离
#随机初始化K个聚类中心(满足数据边界之内)
def randCent(dataSet,k):#定义样本数据和k值为变量
n=shape(dataSet)[1]#得到数据样本的维度
centroids=mat(zeros((k,n)))#初始化为一个(k,n)的矩阵,每一行的元素个数都为样本数据的维度。因为我们取得的k值和样本数据的维度相同,所以在取k值时,是在每一个维度都随机取值
for j in range(n):#遍历数据集的每一维度,计算所有k值每一维度的取值。也就是第一次循环计算所有k值的第一维度;第二次循环计算所有k值的第二维度;...一直到第n次循环计算所有k值的第n维度。
minJ=min(dataSet[:,j]) #得到该列数据的最小值
rangeJ=float(max(dataSet[:,j])-minJ)#得到该列数据的取值范围(最大值-最小值)
#k个质心向量的第j维数据值随机为位于(最小值,最大值)内的某一值
centroids[:,j]=minJ+rangeJ*random.rand(k,1)#也就是先计算所有k值在这一维度的取值。取值 = 最小值+(最大值-最小值)*(0~1)随机数
return centroids#返回初始化得到的k个聚类中心
#k-均值聚类算法
#@dataSet:聚类数据集
#@k:用户指定的k个类
#@distMeas:距离计算方法,默认欧氏距离distEclud()
#@createCent:获得k个质心的方法,默认随机获取randCent()(将randCent()赋值给createCent
def kMeans(dataSet,k,distMeas=distEclud,createCent=randCent):
m=shape(dataSet)[0]#获取数据集样本数
clusterAssment=mat(zeros((m,2)))#初始化一个(m,2)的矩阵,第一列用于放置每一个样本数据归于哪一个聚类中心(也就是当前样本的聚类结果),第二列用于放置平方误差
centroids=createCent(dataSet,k)#centroids = createCent() = randCent(),即引用之前创建的函数,创建初始的k个质心向量
clusterChanged=True#聚类结果是否发生变化的布尔类型
while clusterChanged:#只要聚类结果一直发生变化,就一直执行聚类算法,直至所有数据点聚类结果不变化
clusterChanged=False#聚类结果变化布尔类型置为false(也就是是说聚类结果并未发生变化)
for i in range(m): #遍历数据集每一个样本向量
minDist=inf;minIndex=-1#每当对一个样本数据进行距离计算时,就初始化最小距离为正无穷;最小距离对应索引为-1(也就是初始化索引为-1,为了方便以后依次叠加搜寻每一个聚类中心
for j in range(k):#循环k个类的聚类中心
distJI = distMeas(centroids[j,:],dataSet[i,:])#计算一个数据点到一个聚类中心的欧氏距离
if distJI<minDist:#如果距离小于当前最小距离(所以初始化最小距离为正无穷是为了方便留下第一个被计算的距离)
minDist=distJI;minIndex=j#直接更新当前距离为当前最小距离;最小距离对应索引对应为j(第j个聚类中心)。重复这样的迭代可以得出最小的距离
if clusterAssment[i,0] !=minIndex:clusterChanged=True#当前聚类结果中第i个样本的聚类结果发生变化:布尔类型置为true,继续聚类算法
clusterAssment[i,:]=minIndex,minDist**2#更新当前变化样本的聚类结果和平方误差
print centroids#打印k-均值聚类的质心
for cent in range(k):#遍历每一个质心
ptsInClust=dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#将数据集中所有属于当前聚类中心的样本通过条件过滤筛选出来
centroids[cent,:]=mean(ptsInClust,axis=0)#计算这些数据的均值(axis=0:求列的均值),作为该类的聚类中心,也就是更新聚类中心
return centroids,clusterAssment #返回k个聚类,聚类结果及误差
```
6.由1.可以看出,k的取值对于我们分类的结果起着非常重要的作用。在应用中,k值一般来说是根据实际情况的需要,人为的确定k值。同时,我们也可以通过不停的调试K值的大小,观察不同的k值产生的分类结果以及误差来判断比较合适的k值