GCN(图卷积神经网络)
前面我们已经学习过了卷积神经网络CNN,其实GCN就是CNN在图上面的应用。在CNN中我们输入的是一张图片,然而随着CNN的广泛应用,我们发现它并不能满足所有的应用。比如,我们对一个群聊内所有人的关系进行分析时,那么这个关系网就是一个图。每个人作为一个结点,都有若干个不确定的人和他关联。在这种情况下,CNN就不能很好地发挥作用,于是在CNN的基础上,我们提出了应用于图的卷积神经网络GCN。
提示:在对GCN进行理解时,可以将GCN的一些部分类比于CNN来学习,对于已经掌握CNN的同学来说可能会比较好理解。
一些数学基础
在这之前,我们需要重温一些基础的高数和离散数学的知识。由于本人数学废柴,而且记性比较差,所以很多简单的定义会写的比较白话,方便我自己能看懂,数学比较好的童鞋可以自行跳过
图的定义:图分为有向图和无向图,都可以用G=(V,E)来表示,V表示结点的集合,E表示有向或者无向边的集合。
邻接矩阵:分为有向图邻接矩阵和无向图邻接矩阵,矩阵的大小为 N×N ,N为图的结点数,矩阵内的元素表示一个顶点和另一个顶点之间的关系(用0和1来表示无或者有),且无向图的邻接矩阵一定是关于对角线对称的。但是有向图的邻接矩阵不一定。
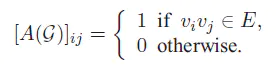
特征矩阵:设 A 是n阶方阵,如果存在数m和非零n维列向量 x,使得 Ax=mx 成立,则称 m 是矩阵A的一个特征值或本征值(如图)

GCN里面的特征矩阵可以类比CNN里面的filter,都是为了提取特征用的
度矩阵:度矩阵是对角阵,对角上的元素为各个顶点的度。顶点vi的度表示和该顶点相关联的边的数量。
无向图中顶点vi的度d(vi)=N(i),且除了对角线以外的所有元素值都为零。

拉普拉斯矩阵:给定一个有n个顶点的图G,它的拉普拉斯矩阵:
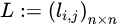
定义为:L=D-A。其中D为图的度矩阵,A为图的邻接矩阵。这样用公式可能有点抽象,我们可以用一个例子来对这个定义进行解释:

GCN的运行机制
GCN是一个在图上进行操作的神经网络。给定一个图 G=(E,V) ,一个 GCN 的输入包括:
一个 N×N 的对于图结构的表示的矩阵,例如 G 的邻接矩阵 A。这个邻接矩阵实际上就是我们根据实际情况输入的一个结构图的邻接矩阵。比如,一个群聊里面所有人的人际关系,把人作为结点,两个人之间是否认识作为两个结点之间的关系,就可以构成一个图G,A就是这个图G的邻接矩阵。这个邻接矩阵可以类比为CNN里面输入的图像的三维矩阵。
一个输入特征矩阵 X,其维度是 N×F ,其中 N 是节点的数目(即E),F 是每个节点输入特征的数目。这个特征矩阵是用来对输入的邻接矩阵进行特征提取的。可以理解为,特征矩阵的每一行都对应于一个结点的F个特征数目。
GCN 的一个隐藏层可以写成 Hi=f(Hi-1,A),其中 H0=X 并且 f 是一个 propagation。每 层Hi 对应一个 N×Fi 的特征矩阵,矩阵的每行是一个节点的特征表示。在每层,这些特征 通过 propagation rule f 聚合起来形成下一层的特征。通过这种方式,特征变得越来越抽 象在每一层。在这个框架中,GCN 的各种变体仅仅是在 propagation rule f 的选择上有 不同。
一个简单的 Propagation Rule 一个可能最简单的传播规则是: f(Hi,A)=σ(AHiWi) 其中 Wi 是第 i 层的权重并且σ是一个非线性激活函数例如 ReLU 函数。权重矩阵的维度是 Fi×Fi+1;也就是说权重矩阵的第二个维度决定了在下一层的特征的数目。如果你对卷积神 经网络熟悉,这个操作类似于 filtering operation 因为这些权重被图上节点共享。 可以简单表示为:

说实话,关于GCN的隐藏层计算这段话很难理解,这个公式也很难懂,所以很难真正看明白GCN的隐藏层在进行运算时究竟是如何计算的,计算的结果到底收到什么因素的影响,而且我在网上能查阅的资料中也基本上都是把这段话复制粘贴一下,没有浅显易懂的理解(至少对于我来说是这样的)。所以我们可以举一个简单的例子,然后再回过头来看这段话,理解起来就会容易得多。
一个简单的例子
首先来看这个有向图
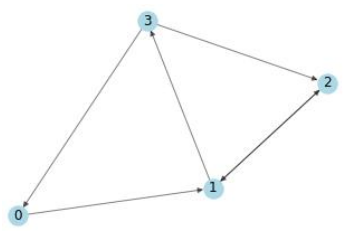
这个图的邻接矩阵表示是:(为了方便,直接用代码表示,后期可以直接运行证明)
import numpy as np
A = np.matrix([
[0, 1, 0, 0],
[0, 0, 1, 1],
[0, 1, 0, 0],
[1, 0, 1, 0]],
dtype=float )
X 为输入的特征向量,我们直接取值,维度为(N,F0),其中 N 为结点个数,F0为输入向量的特征维数。接下来,我们需要特征!我们根据每个节点的索引来生成两个整数特征。这会使得后面手动 验证矩阵的计算过程更容易。
X = np.matrix([
[i, -i]
for i in range(A.shape[0])
],
dtype=float)
X = ([
[0, 0],
[1,-1],
[2,-2],
[3,-3],
])
所以Input = A*X = ([
[1,-1],
[5,-5],
[1,-1],
[2,-2],
])
我们会发现,输入的特征矩阵和相乘后输出的矩阵维度都是4*2,都可以理解为每一行都是一个结点的F个特征数。而在相乘的过程中,我们不难发现,每一个元素的每一个特征值,都是由该元素的邻居的特征值之和组成的。我们不妨分解的再详细一点:
Input[0,0] = 0×0 + 1×1 + 0×2 + 0×3 = 1
Input[0,0]对应的是第一个结点的第一个特征的计算值,这个值的计算结果是由它的邻居的特征值之和计算得来的。
使用 Propagation Rule 即将出现的问题
在这个运行机制中,我们很容易发现一些问题
A*X 的结点表示中,并没有加自己的特征值。
一个节点的聚集表示不包括它自己 的特征,这个表示只是它的邻居节点特征的聚集,所以只有有一个自循环的节点才会 包括它自己的特征在聚集中。
邻接结点多的结点的特征值会大,少的特征值就小。
具有很大度数的节点将会有 很大的值在它们的特征表示中,而具有很小度数的节点将会有很小的值。这些可能造成梯度消失或者梯度爆炸。这对于随机梯度下降也可能是有问题的,随机梯度下降通 常被用来训练这样的网络,而且对于每个输入特征的值的范围是敏感的。
解决方法
为了解决第一个问题,我们可以通过简单地给每个节点加入一个自循环(self-loops)。在实践中,这可以通过把单位矩阵 I 加到邻接矩阵 A (在应用传播规则之前)上来实现。
为了解决第二个问题,我们使用归一化的技巧。
将自循环和归一化的技巧结合起来,并且引入权重参数和激活函数,一个图卷积神经网络的大致流程就出来了,我们依然取上面的计算作为例子
1,取权重参数: W = np.matrix([ [1, -1],
[-1, 1] ])
取特征矩阵:X = 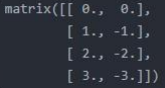
2,自循环处理:
(1)设置单位矩阵I:I = np.matrix(np.eye(A.shape[0]))
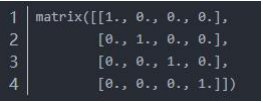
(2)将单位矩阵和邻接矩阵A相加:A_hat = A + I
A_hat = ([[1, 1, 0, 0],
[0, 1, 1, 1],
[0, 1, 1, 0],
[1, 0, 1, 1]],
dtype=float )
3,归一化处理:
(1)首先计算图A_hat的度矩阵D_hat(这里应该是计算出度和入度都可以的)
D_hat = np.array(np.sum(A_hat,axis=0))[0] #计算矩阵A的每个节点的入度存放在一个数组中
D_hat = np.matrix(np.diag(D_hat)) # 变成一个完整的度矩阵
D_hat =
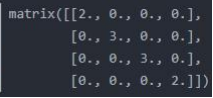
(2)转换邻接矩阵:取度矩阵的负一次方(D_hat**-1)乘上 A_hat。
(3)D_hat**-1 * A_hat * X * W = 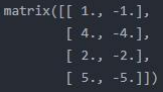
注:在计算过程中,输出的特征表示的维度(也就是特征数目)是由输入的特征矩阵X的列数决定的。如果我们想要减少输出特征表示的维度,我们可以减少权重矩阵的规模。
加入激活函数
我们选择保持特征表示的维度并且应用 ReLU 激活函数。
relu(D_hat**-1 * A_hat * X * W)
matrix([[1., 0.],
[4., 0.],
[2., 0.],
[5., 0.]])
这就是一个带有邻接矩阵,输入特征,权重和激活函数的完整的隐藏层。
从图的结构来理解
在计算机的程序运行中,我们是把图转化成了矩阵来进行处理,同时我们也可以从图的结构的角度来简单理解一下图卷积计算的过程。过程比较不太详细,但是更加直观,有助于形象地理图卷积网络。
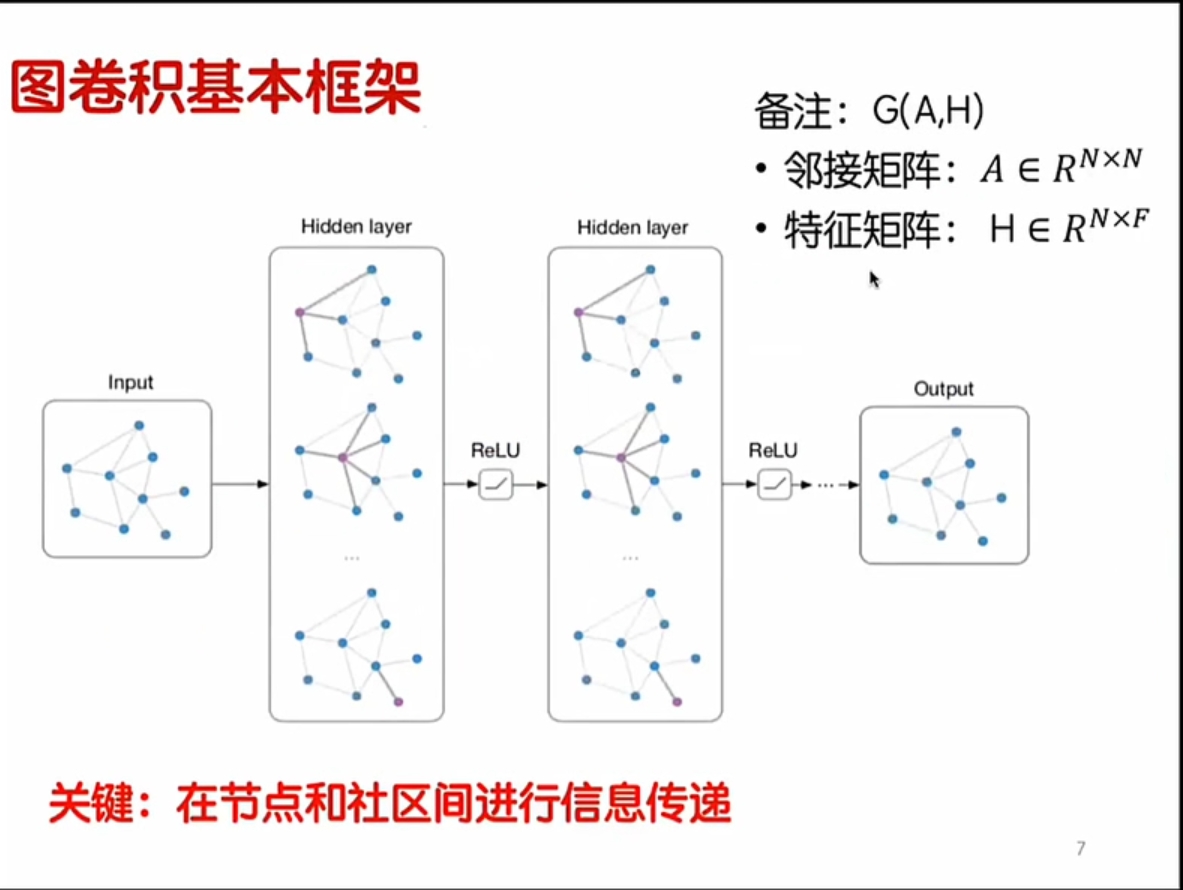
这个图卷积神经网络的第一层是输入的图,在第二层Hidden layer中,每一个结点都和特征矩阵进行计算,每一个计算出来的结果都会在节点处被更新,再经过一层Relu激活函数之后,进入新的隐藏层,重新进行计算。