词向量-word2vec
首先我们来看几个概念。
什么是embedding
embedding就是我们机器学习总的嵌入传播层。就是用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。这个embedding向量的性质是能使距离相近的向量对应的物体有相近的含义,比如 Embedding(复仇者联盟)和Embedding(钢铁侠)之间的距离就会很接近,但 Embedding(复仇者联盟)和Embedding(乱世佳人)的距离就会远一些。
但是用向量来表示一个物体,这是词向量的工作。而Embedding是一层具体的操作,那么Embedding的作用到底是什么呢?
首先我们来看一张图。
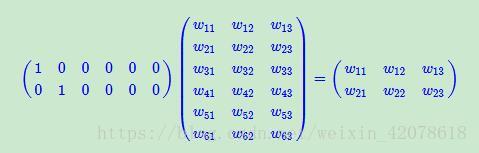
这是一个非常简单的矩阵乘法。
假设:我们有一个2 x 6的矩阵,然后乘上一个6 x 3的矩阵后,变成了一个2 x 3的矩阵。也就是说,通过这个矩阵乘法,我们把图中的数字矩阵缩小了一半左右。这就是Embedding层额用处,通过矩阵乘法,在不损失原矩阵信息的前提下,把输入的矩阵的规模降低许多倍,或者说,降维。尤其是在应用One-Hot Encoding(独热编码)来进行词向量的表达时,Embedding的作用就显得尤为重要。
简单来说,Embedding能够用低维向量对物体进行编码还能保留其含义的特点非常适合深度学习。
One-Hot Encoding(独热编码)
独热编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。
先来举一个简单的例子进行理解:
feature1= [“male”, “female”]
feature1= [“from Europe”, “from US”, “from Asia”]
feature1= [“uses Firefox”, “uses Chrome”, “uses Safari”, “uses Internet Explorer”]
如果我们将以上特征组成的数据直接用数字表示:
[“male”, “from US”, “uses Internet Explorer”] 表示为[0, 1, 3]
[“female”, “from Asia”, “uses Chrome”]表示为[1, 2, 1]
我们可以发现,这些数字并不是连续有序的,所以不能直接应用在分类器中(分类器默认数据是连续的),对于这个问题,One-Hot Encoding可以解决。
使用独热编码转化为:
feature1=[01,10]
feature2=[001,010,100]
feature3=[0001,0010,0100,1000]
所以对于每一个特征,如果它有m个可能的值,经过独热编码后就会变成m个二元特征,并且这些特征互斥,每次只有一个激活。因此,数据就变成了稀疏的。
然后
神经语言模型(NNLM)
在学习word2vet之前,我们先来了解NNLM。NNLM全称为Neural Network Language Model,是一种用于自然语言处理的模型。
首先,One-Hot vector是一种常用于自然语言处理的词向量的表达方式。比如说,一个词库或者说一个字典里面一共有V个单词,那么用One-Hot vector来表示的话,一共有V个单词,就是一个长度为V的低维向量,也就是共有V个状态,每一个单词对应的词向量的状态是:在这个长度为V的向量中,这个单词所在的位置为1,其余位置都为0。我们用W来表示这个单词对应的词向量,也就是我们所说的一个单词对应的独热编码。
这个模型的作用是,用给定单词的前n-1个单词(的独热编码)来预测第n个单词(的独热编码)是什么。
模型的输入:W1,W2,,,,Wn-1,用来预测Wn的值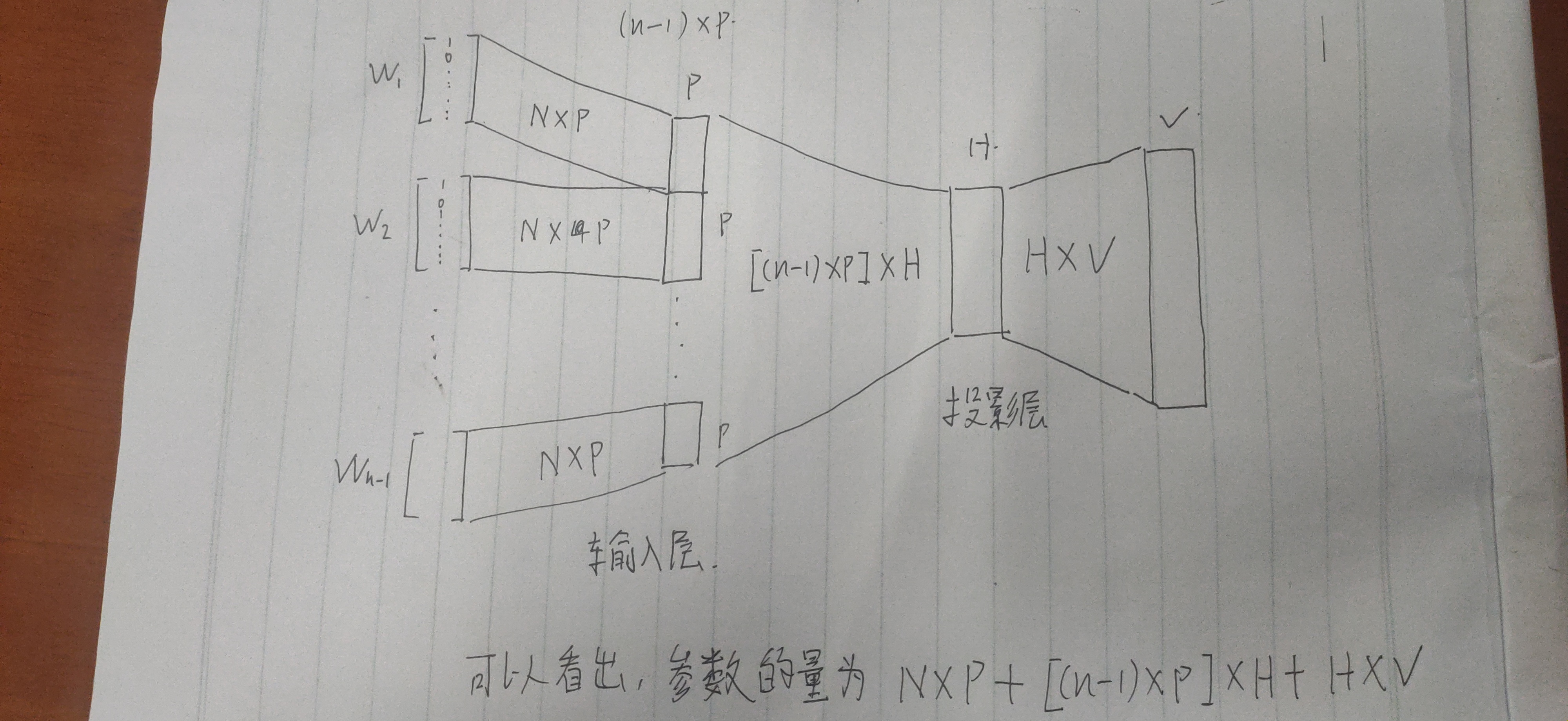
word2vec
word2vec分为两个模型,CBOW和skip-gram。
CBOW
CBOW的作用是根据一个单词的上下文来预测这个单词。
具体的流程是:输入单词Wt的前c个单词Wt-c,Wt-c+1,,,Wt-1和后c个单词Wt+1,Wt+2,,,Wt+c,预测单词Wt
具体流程如下: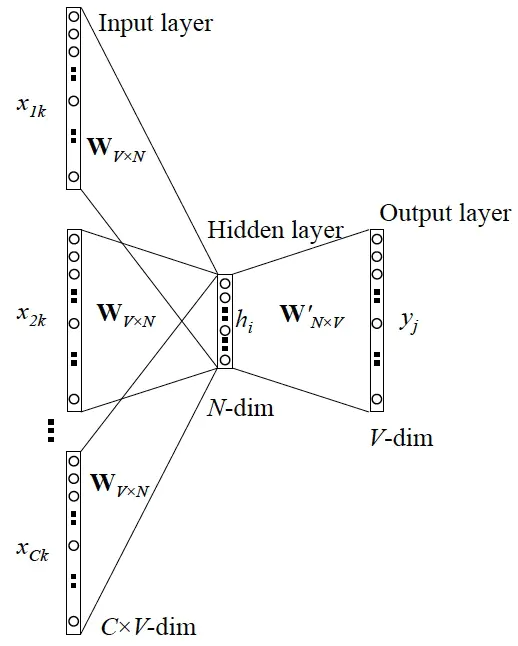
skip-gram
skip-gram和CBOW的作用相反,根据一个单词来推测上下文。
即输入一个单词Wt,来预测前后c个单词。
具体流程如下: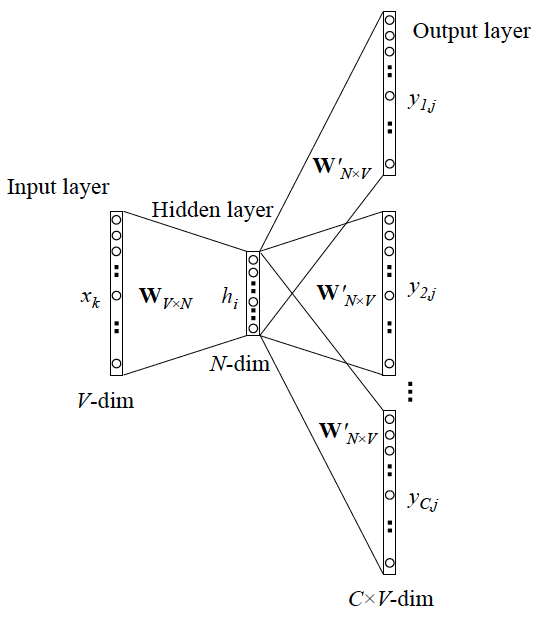
不难看出,其实就是把CBOW的模型反过来。
而这两个模型的参数量都是:V*N+N*V
我们可以看出,和NNLM相比,这两个模型的参数量明显少了很多,复杂度也更低。